
I’ve heard this question being asked multiple times, in forums, blog posts and every single client that doesn’t trust the performance of the Power BI desktop app. So I’ve set myself the challenge to find this out while exploring the versatility of Power Query M language.
One of the most powerful data structures that M has in its arsenal is the List. I’ll start by creating a simple list of numbers.
= {1..1000}
Let’s Apply this query and check the result in the Data Model.

This list looks like a table, acts as a table – then it must be a table. While I’m here, I’ll change the Data Type of the column Query1 from Text to Whole Number. This way, I’ll save the memory footprint for the next time I try to load as much data as possible in this single-column table.
Next step – construct the biggest list possible.
= {1..3000000000}
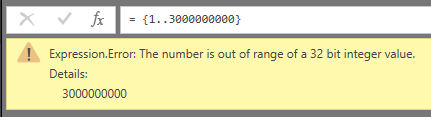
And I’ve hit my first limit. Another try with 231-1.
= {1..2147483647}
Success! But not for long, as once I apply the changes and wait for the Query Changes to be committed to Data Model, at around 2,000,707,684 loaded records, I was faced with another error.

I’ve tried to repeat the process with a smaller list and got my first success at 1,999,999,981 records.

Which produced a 29GB file.

That’s a lot of records, and only to add them to the Data Model I needed 55GB of memory.
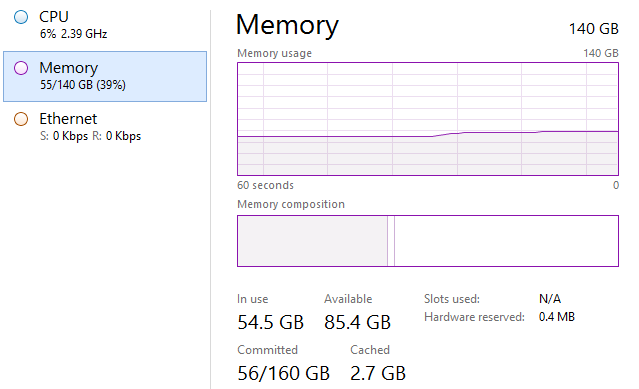
Not too bad for a desktop application.
What about if I wanted to load lots of data that is not that unique? Say 232-2 of ones?
List.Generate(()=>[counter=-2147483647,uno=1], each [counter]<2147483647, each [counter=[counter]+1, uno=1], each [uno] )
![]()
This query completed in no-time, and with very little memory footprint as the entire msmdsrv.exe service stayed within the 1GB limit. The output saved on disk occupied 191KB. Go compression!
How about the wideness of data? I used a different set of queries to find the limit.
I’ve hit gold with :
=#table(null,{{1..15986}})
Which resulted in a 167MB file.
And the imprecise errors that kept popping up were:
