
Recently I started exploring the limits of standard charts in Power BI and ended up drawing all sorts of mathematical … More
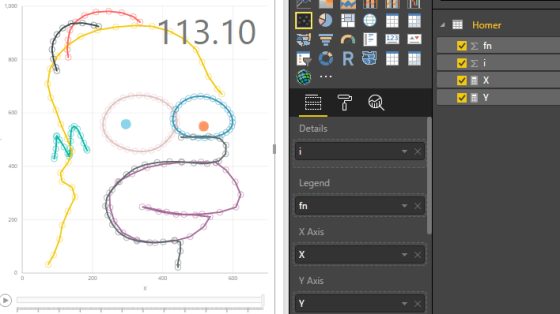
Experiments in Power Query & DAX
Recently I started exploring the limits of standard charts in Power BI and ended up drawing all sorts of mathematical … More

Yet another method of retrieving Power Queries from Power BI workbooks

Using R.Execute() in #Power Query to get the connection details to the $Embedded$ tabular model

The R ways in #PowerQuery. How R.Execute() can be used for other non-statistical related tasks #PowerBI

How to do matrix multiplication in Power Query
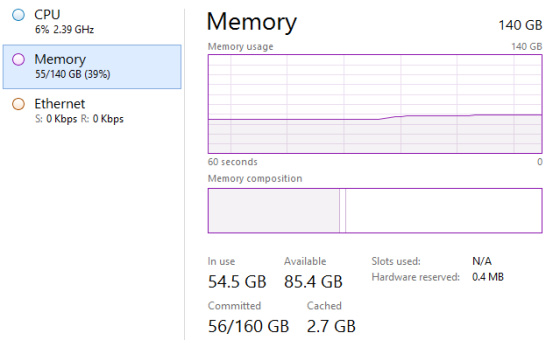
Going through the steps of fitting 4,294,967,294 rows of data or 1,999,999,981 unique values and 15,986 columns into a Data Model table while using 55GB of RAM.
