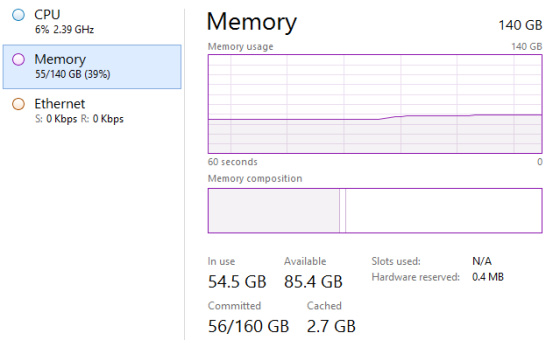
VertiPaq powers Microsoft’s in-memory column store tech, from PowerPivot in Excel to Power BI models. I’ve been on a mission to decode VertiPaq and integrate it into a DuckDB extension, enabling cross-platform data integration. Starting with PBIX files, I’ve navigated complex compression layers, metadata, and file structures. Using tools like Kaitai Struct and diving into Microsoft specs, I’ve managed to parse enormous PBIX files in fraction of a second. The DuckDB-PBIX-extension showcases the potential of “write once, run everywhere.”